Talk @ EuroVis'21
This state-of-the-art report was presented at EuroVis'21.
Challenges and Observations from the Paper
Before we get to the detailed methodologies of coding and paper collection, here is a brief summary of our main findings:Evaluation Focus
- Bias towards algorithm-centered evaluations
- Multiple, tailored evaluations rather than one broad one
Participants
- On average, six participants in the surveyed evaluations
- Simpler replacement tasks for evaluation at scale are not always a good fit
- Personal characteristics and experiences are rarely considered
Lack of Ground Truth
- Exploratory or personalized analysis results
- Multi-stage evaluations pass to further participants for evaluation or ranking
- Very diverse set of methodologies and study protocols.
- More detailed evaluation of model- and explanation properties than of human factors.
- Incomplete study reporting.
- No significant differences between the evaluation of supervised and unsupervised machine learning.
Summary of Findings
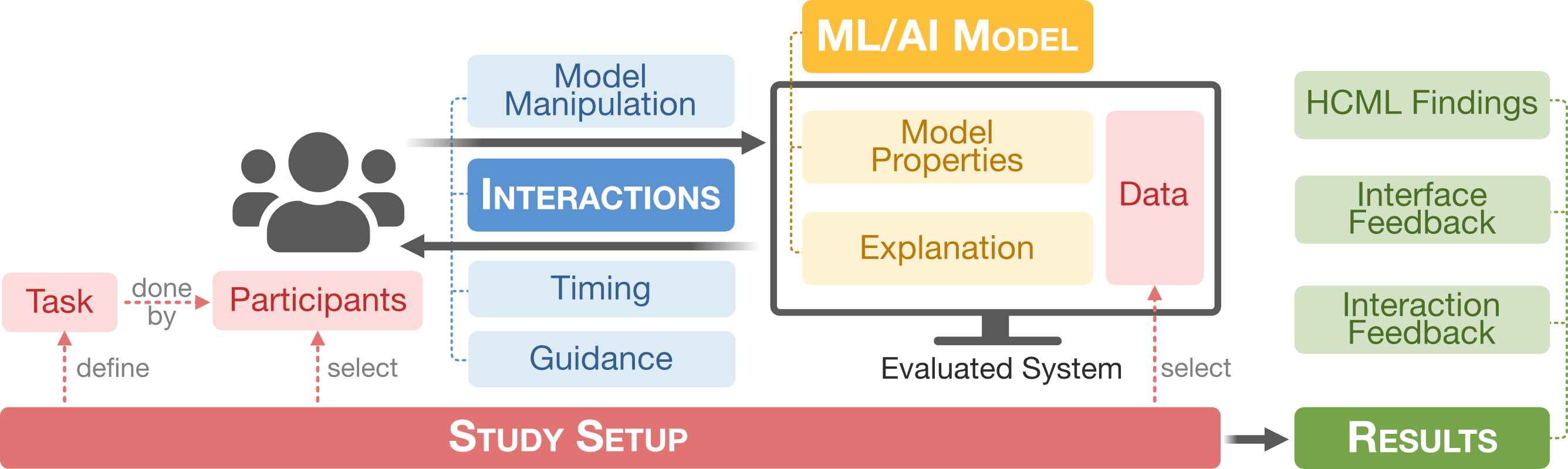
Below, we summarize the findings for each of the four aspects study setup, model and explanations, interactions, and reported results. Many more details can be found in the paper.Study Setup
- We collect eleven dimensions in the three categories study setup, participants and tasks and data.
- Study protocols and methodologies for data collection
- Participant training and performed tasks
- Used data types
- Demographics of study participants
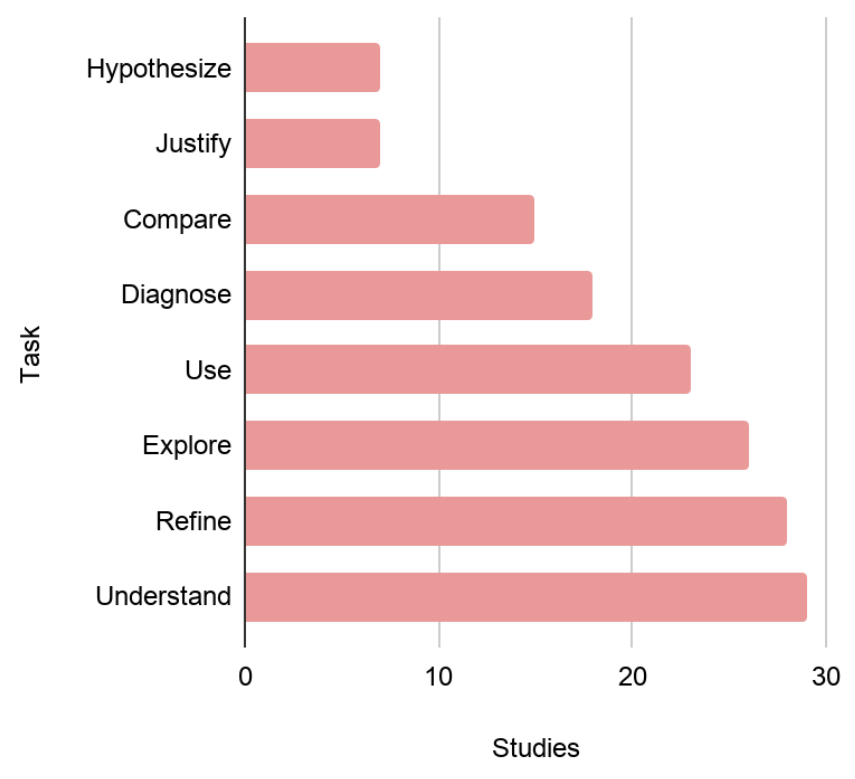
Most studies evaluate understanding and refinement. Few studies consider hypothesize creation or model justification. Several studies let participants use models without model-specific tasks.
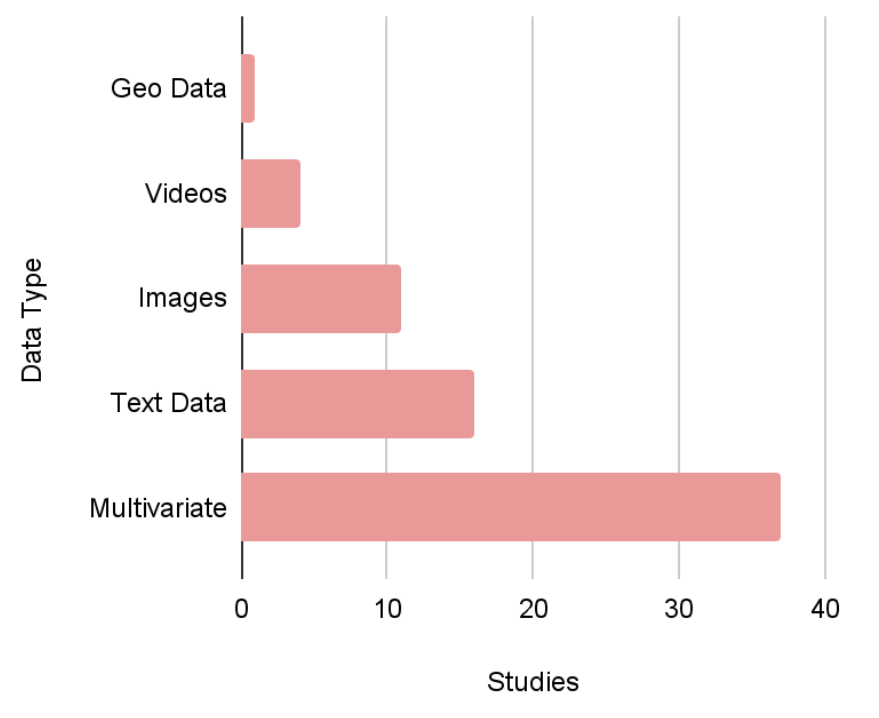
The most frequently used datatype was multivariate data, followed by text data and images. Only few systems deal with videos or geographical data.
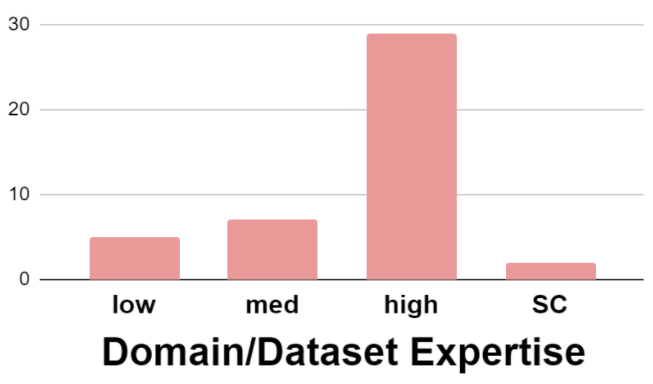
Typically, participants are experts in the system domain or the dataset used during the study. Few papers evaluate the influence of expertise on study outcomes (SC).
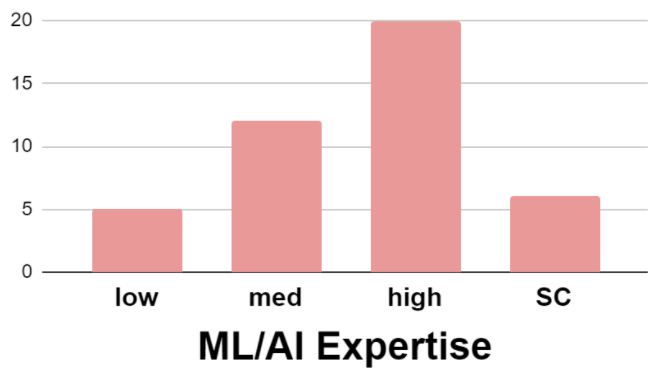
While most participants are experts in machine learning, several papers rely on participants with intermediate knowledge. Few papers evaluate the influence of expertise on study outcomes (SC).
Model and Explanation Properties
- We distinguish between six XAI properties concerning models and four properties of explanations
- Properties of models are evaluated much more frequently than properties of evaluations
- We found a frequent mismatch between motivated and evaluated properties
- Properties of models and explanations are often evaluated and reported in more detail than human-related factors
Some papers evaluate the participant's perception of transparency with or without making it a study condition (measured and measured condition, respectively).
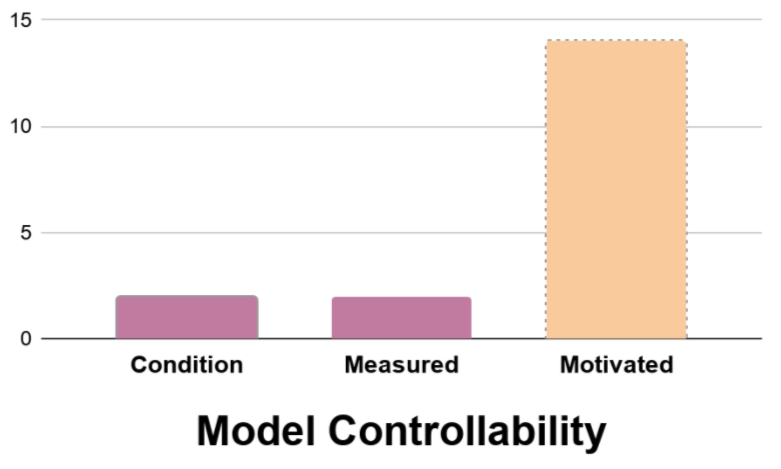
Some papers manipulate controllability as a study condition (measured) or evaluate the participant's perception of controllability (measured).
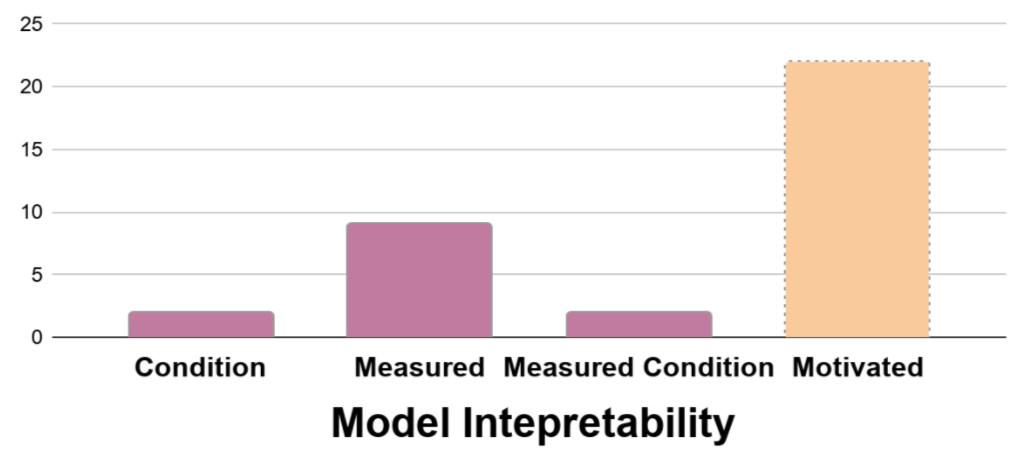
Interpretability is the model property most frequently measured. Still, more papers motivate this property without evaluation.
Interaction
- We survey eight dimensions in the three categories model manipulation, timing, and guidance.
- Most studies focus on the training or post-training phases, with only four covering data selection and data preprocessing.
- We found a relatively equal distribution of direct and indirect model manipulation
- Guidance is rarely evaluated at all, and no study set out to specifically evaluate the provided guidance
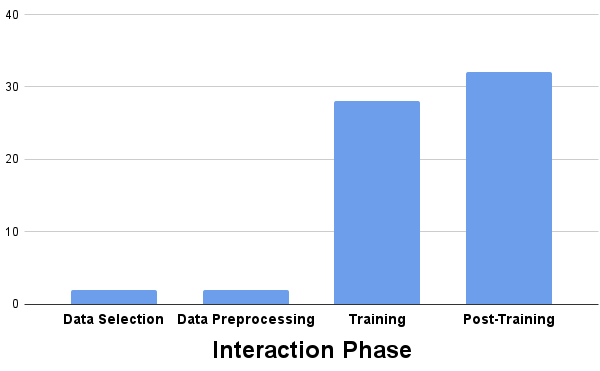
Only few papers evaluated user tasks from the data selection or data preprocessing phases of the machine learning pipeline. Note: Papers can evaluate tasks from different phases.
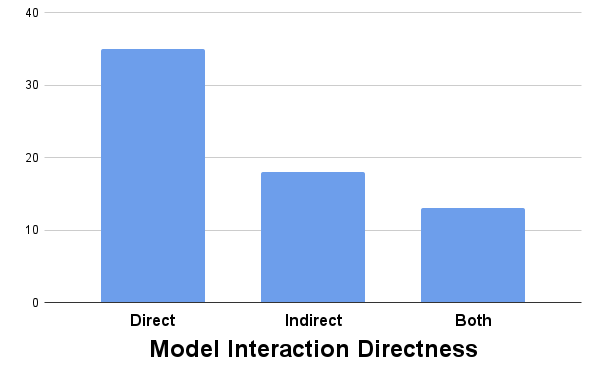
While more papers offer direct interaction possibilities with the model, a significant number employ indirect model manipulation.
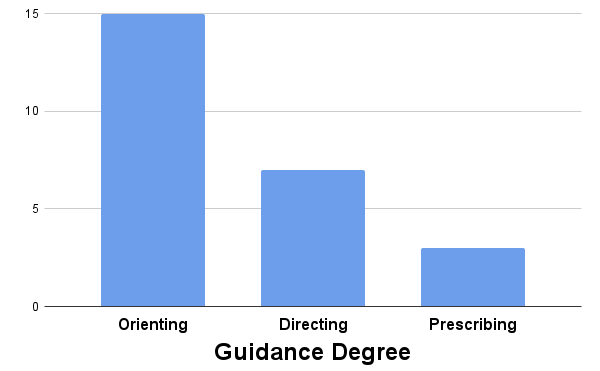
While guidance is infrequently evaluated in detail, most papers that provide guidance rely on less intrusive orienting guidance. Note: Papers can employ multiple guidance degrees.
Reported Results
- To capture the reported results, we ran three IHTM topic models on the main findings and interface- and interaction feedback, respectively.
- Due to the diverse reporting formats and varying levels of detail, the topic models remained relatively high-level.

The interaction topics suggest that interaction is often used for customization and to control models.

The interface feedback topics highlight the usefulness of explanations and interactions for interpretability.

The topics for main findings relate to core tasks, including understanding, interpretability and explainability.
Next Steps
To support, in particular, junior researchers in developing more targeted study designs, we provide both a checklist for study design and a checklist for study reporting in human-centered evaluation of human-centered machine learning.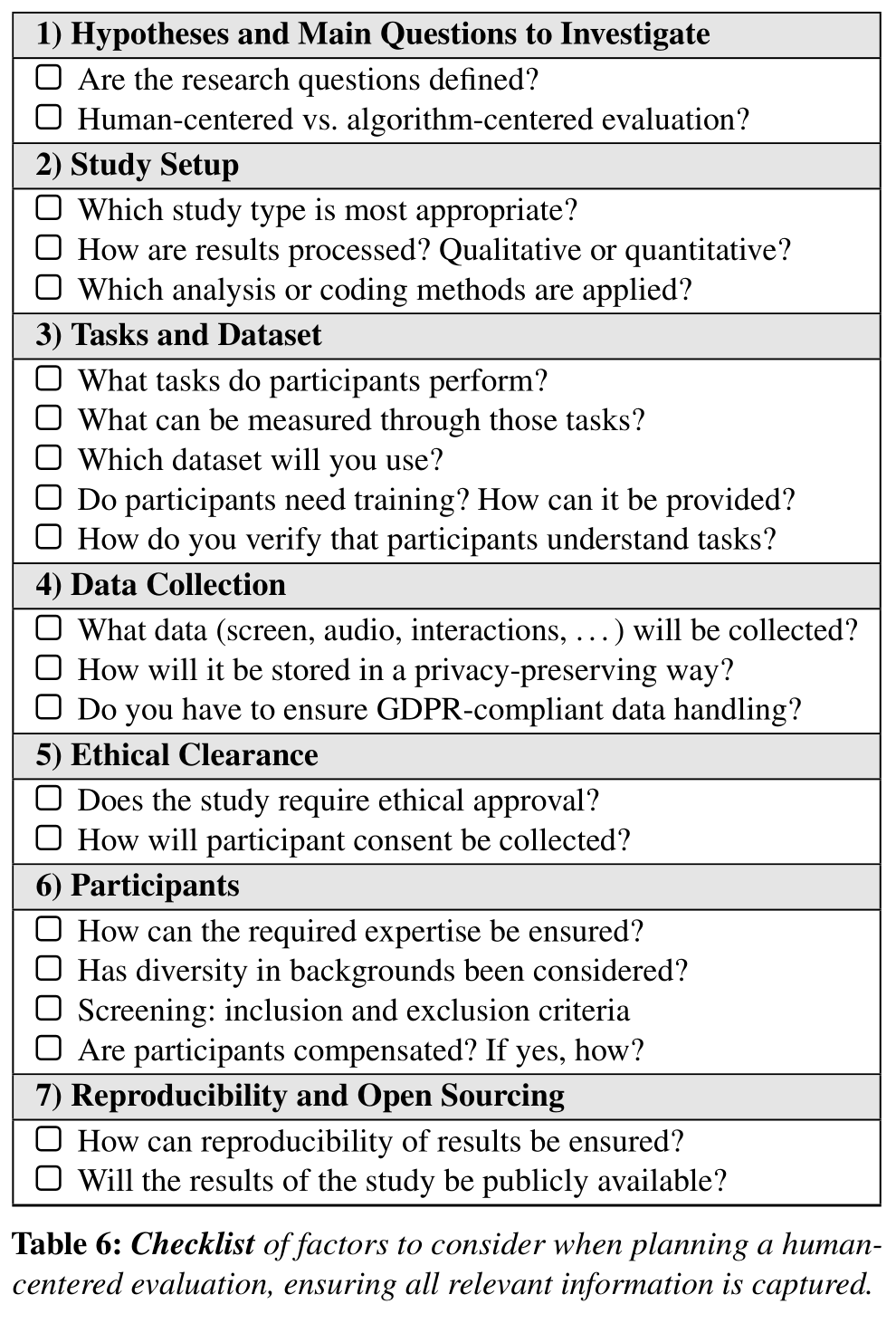
Checklist for Study Design
This checklist aims to facilitate the creation of study designs and ensure that relevant factors are covered before participants are evaluated. While most points should be self-explanatory, here is a brief summary:- Ordered checklist to work through during the ideation and setup of human-centered evaluations
- For some survyed papers it was not clear what they aimed to evaluate -- hence we start with the definition of research questions and the general evaluation approach. Depending on the hypothesis, human-centered or algorithm-centered evaluation perspectives need to be balanced differently.
- In addition to the tasks that participants perform, consider whether participants will require training before they can complete the tasks, and to what extent they will be trained before the study begins.
- Participants are likely a diverse set of people of different age, gender, cultural background, and expertise in both the evaluated domain and dataset, and machine learning in general. Ensure that this diversity has been considered appropriately and define requirements for study participation.
Template for Study Reporting
This detailed template can be filled out and included in a paper's supplementary material to ensure that information required to judge the study's findings are provided. Furthermore, it provides an overview of aspects that should be considered when reporting results.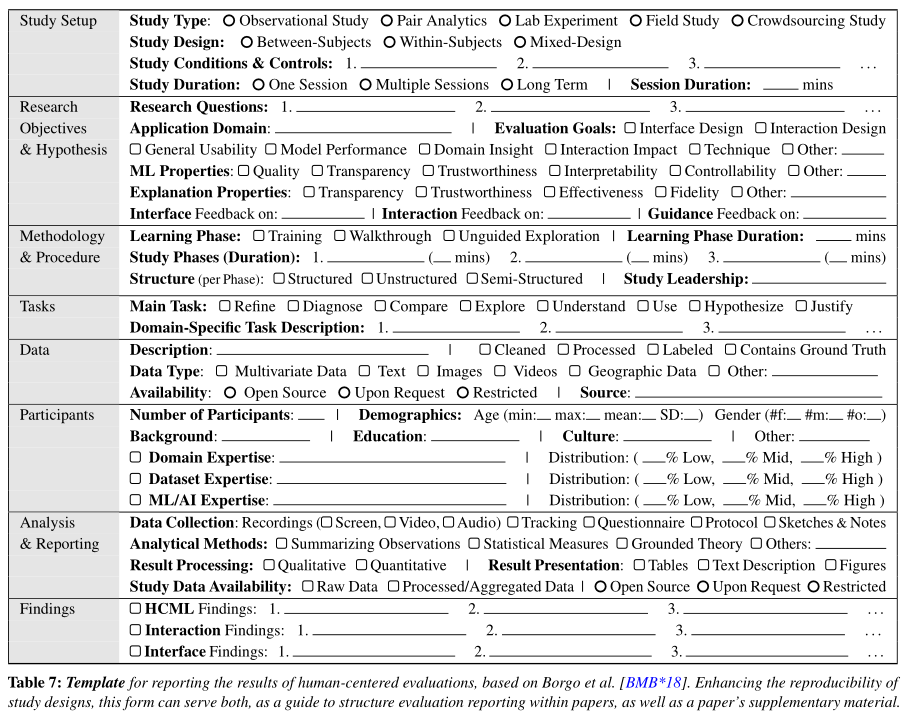
Opportunities and Calls for Action
Our survey highlights several opportunities for future work in human-centered evaluation of human-centered machine learning:
Structured Evaluation Framework
- Need to survey algorithm-centered evaluations
- Derive guidelines for balanced evaluations
Shared Vocabulary
- Ensure matching understanding of common XAI terms
- Consider providing definitions of used terms in your next paper
Open Access & Reproducibility
- Open access not only for systems and results, but also for evaluation frameworks if you create them
Based on our survey results, we call on the community to consider evaluation papers as one possibility to tackle the issue of current human-centered machine learning papers being too complex to be holistically evaluated in a single paper: